An excellent companion to Rée’s superb Witcraft, his history of how philosophical ideas made their way into English (often with a considerable delay). The chapters here on Kierkegaard and Sartre neatly fill some gaps in that earlier book’s narrative, as it (mistakenly and frustratingly, in my view) ended the story largely with Wittgenstein. (Yes, Kierkegaard was earlier, but didn’t get translated into English until the early-mid 20th century.)
The introductory interview was also a nice touch, with Rée’s dislike of histories of philosophy – and especially of Bertrand Russell’s, and of Russell more broadly – an entertaining educated rant that helped shift my perspective on what has become one of my favourite genres of book over the last few years. I knew it’s not just me who sometimes, when reading the original works rather than someone else’s summary of them, struggles to understand and needs to re-read paragraphs repeatedly – but it was very reassuring to hear that the same is true for Rée.
Philosophy is hard, basically. Intellectual biographies and histories of philosophy may make it more accessible – but the point is philosophy is all about the act of thinking, not just understanding ideas.
This feels like a particularly useful insight in the age of GenAI, when it’s easier than ever to find a summary of an idea, and to have someone (albeit a bot) explain a complex concept in simple terms. This may be a shortcut to understanding, but sometimes this can mean your understanding is only superficial – by reaching your knowledge via an intermediary, rather than working at it yourself, you’re likely to be missing nuances and details, as well as to be picking up received wisdom and interpretative assumptions from other people, rather than determining your own understanding.
Taking shortcuts via other people’s interpretations isn’t always a bad thing, by any means – but it’s worth being aware of what you may be missing by doing so. I’m probably never going to read Heidegger’s Being and Time or Sartre’s Being and Nothing in English, let alone in the original German and French. I’ve always known I’m going to be missing something as a result – the summaries of these books that I *have* read have convinced me there are aspects of both I’d find fascinating. But Rée’s emphasis on taking the time to digest philosophical works, to ruminate on them, to make the effort to truly understand them has given me pause.
Much to think about here, in other words – not bad for what is at its core a collection of book reviews.
Bad photo of a good slide on what makes content valuable in an AI era, from Kevin Anderson at the inaugural Source Code event last night.
A successor to the much missed Hack/Hackers series looking at how tech and journalism can come together to do great things, it was unsurprisingly dominated by conversations about AI.
The point about what is valuable about the content we produce was also core to my old colleague Steven Wilson-Beales‘ session on SEO / GEO / AEO / AIO / whatever you want to call it, and what a “zero click” web could look like in practice.
Key points:
– You need differentiation
– You need to add value
– You need to be accessible, relevant, and credible
It’s almost as if E-E-A-T is still a thing!
Also, the lesson we should all have taken from the last decade and a bit of chasing search and social algorithms is simple – diversify.
Don’t get over reliant on any one traffic source. Don’t chase the algorithm, because the algorithm is changing faster than ever – and with AI search, will increasingly adapt it’s findings to every individual.
And a top tip – given AI tools have been trained on existing content, you need to take a careful look at your archives. If they don’t answer the potential needs of an AI bot in query fan out mode, they may need an update.
—
But the absolute key point – and this speaks to a lot of the work I’ve been doing behind the scenes lately – It’s no longer enough to focus your SEO / GEO efforts on optimisation of individual pages.
You need to see your content as part of a broader system – because the bots are no longer looking for just one page to rank at the top of a list, they’re looking for the right information to answer the query. If they can’t get it from you, they’ll get it from someone else. (Or just make it up…)
I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
These systems don’t just read what you publish and serve up the most relevant parts – they synthesise it, blending multiple sources based on patterns they infer across a wider field of signals:
– everything you publish
– everything others publish about you
– everything they consider adjacent or comparable
They’re also not just looking at what’s being said now. They’re conflating and combining the accumulated traces of how your organisation expresses itself over time – across campaigns, content, product information and everything in between.
Repetition and consistency may help, but they won’t just pick up what you intend. They absorb whatever is most legible – including contradictions, gaps, and overlap with competitors.
If your positioning isn’t distinctive, you’ll get flattened into the category. If your communication isn’t coherent, the model will reconstruct a version of your brand from whatever patterns it can find. And when it comes to facts and details – where accuracy actually matters – these systems are still unreliable enough to pose a real risk.
This is where a focus on structured data starts to look like a promising way forward. That was my first assumption. But it’s becoming increasingly clear that this isn’t going to be enough.
—
The key is to remember that these systems don’t *understand* information. They generate outputs by following probabilistic sequences – patterns shaped by the data they’ve seen.
It’s a sophistiated form of word association. Structure helps, but only where it clarifies those patterns to nudge the model to follow the path you’d prefer.
Over time, what you’re really creating – deliberately or not – is a set of associations the LLM learns to treat as related. What we’d normally think of as a brand “narrative” sits inside that – not as something the model understands directly, but as a pattern of connections it learns to reproduce.
—
This means “AEO” should be considered less about optimising individual outputs, and more about the long-term shape of the signals you generate – across teams, markets and years.
I’ve been doing some work on this recently, trying to make that problem more tangible and diagnosable in practice. Still early, but the direction of travel feels clearer.
The brands that show up well won’t just be the ones optimising for visibility. They’ll be the ones whose overall pattern of behaviour is coherent enough that even a probabilistic system can’t easily misread what they are.
Most of what the “GEO” crowd are peddling now *sounds* logical with all its talk of structured data and query fan outs, and is more or less exactly what I was arguing back in late 2023 / early 2024.
I was wrong then, and they’re still wrong now. As Orange Labs founder Britney Muller puts it:
During training, LLMs process text from across the web, but they don’t log URLs, store sources, or remember where anything came from. What’s left is a frozen statistical snapshot (Gao et al., 2023). Not an index. Not a database.
Search engines do the crawling, indexing, and retrieval. LLMs lean on them heavily to surface real-time info (because on their own, they can’t).
Stop optimizing for ‘AI.’ Optimize for search engines (so retrieval-based AI can cite you) + earn third-party coverage (so the model already knows you before the prompt is typed).
That’s not to say query fan out logic (and other “GEO” tactics) doesn’t have its place in content planning – it does. But all this *really* is is a fancy name for an FAQ page (with less emphasis on the “F”). That’s been a core idea in SEO for over two decades. And pretty much all the rest of the “GEO” advice is similarly reskinned old school SEO – from keyword stuffing to linkfarm spamdexing – that Google quietly filtered out years ago.
There’s an awful lot of snake oil being flogged out there at the moment. If some of it seems to work, it’s more by accident than design.
This, on the resurgence of the Rise of the Robots fears about the threat of widespread AI job losses, gets some of the way to articulating the niggling issues I have with this apocalyptic narrative:
Even if you do believe the technology has got or can get good enough to replace workers at scale, the economics simply don’t make sense.
Of course, we’ve spent the last two decades witnessing many, many things that made no economic sense yet that happened anyway thanks to a combination of complacency, willful ignorance, ideology, bloody-mindedness, and spite. Just because something makes no economic sense doesn’t mean it won’t happen.
But despite non-AI industry stocks having been hammered over the last couple of weeks, think what needs to happen to enable this AI revolution. Most developed nations had energy and clean water supply challenges even before factoring in a data centre building boom. We still have a deep reliance on rare earth metals for the hardware that the AI needs to function (the clue’s in the name).
What happens to prices when demand surges to unprecedented levels and supply struggles to keep up? And how does that change the balance sheet projections when deciding whether to replace human workers with a grandiose form of a new SaaS subscription, whose monthly costs and reliability could shift at any moment?
Remember the $7 *trillion* Sam Altman was asking for to invest in infrastructure? That’s likely to be a substantial under-estimate of the amounts needed given how much every industry upstream of the AI companies is already struggling to meet their projected needs.
Back when ChatGPT 3.5 came out, I was telling anyone who’d listen that it was going to disrupt search and publishing.
In early 2024, while at PwC, I started pitching new content formats to address this – intended to help capture whatever the GenAI equivalent of search ranking was going to be. “GEO” before this label stuck (I was calling it AIO at the time).
My thinking then was based on what seemed to be a logical, structured approach – similar to the “query fan out” advocates you’ll see in the “GEO” space today. (Basically label the hell out of your content, anticipate and answer the questions your target audience is likely to ask, as that structure should help the AI understand the context more easily, and so encourage it to pull from your page rather than someone else’s. Effectively a slightly deeper version of an old school Q&A or FAQ piece…)
But as I dug deeper it soon became clear that the challenge with LLM-based GenAI (from a model visibility perspective) wasn’t to do with clarifying the intended meaning of the information you want the model to ingest and regurgitate, as I first thought. (“These things can process unstructured data, but they’ll process *structured* data easier – so let’s structure it for them.”)
Instead it’s that these systems – despite being called Large *Language* Models – don’t actually understand language, or context. “Logic” to them is a meaningless concept; not only that, they have no concept of what a concept even is.
—
Tokens aren’t words, and don’t have meaning independently – they only appear to have meaning when combined into words.
Tokens create the illusion of being words (and having meaning) because of the probabilistic nature of these tools, when working with them using language as the system interface. This creates an environment in which they’re working within the rules of language, so can produce output that makes sense – even if they don’t “understand” what they’re saying.
But URLs aren’t language, and don’t have linguistic rules or any consistency from site to site in terms of information architecture. Every site’s URL structure is similar, but different.
And as LLMs don’t really understand structure (except as recognisable, predictable patterns), this makes accurately relating URLs a significant challenge for current LLM-based GenAI tools.
—
This is a structural challenge, baked into the very nature of these models. Despite what many GEO “experts” are now claiming, if your goal is to generate links and traffic from GenAI results, it’s not going to be an easy one to engineer if you’re working from outside that system.
It may be possible to tweak model outputs to improve this and increase URL attribution accuracy, but a) it won’t remove the underlying structural constraints, and b) what would be the incentive for the GenAI companies to do this?
“What looks like higher productivity in the short run can mask silent workload creep and growing cognitive strain as employees juggle multiple AI-enabled workflows…
“Over time, overwork can impair judgment, increase the likelihood of errors, and make it harder for organizations to distinguish genuine productivity gains from unsustainable intensity.”
As so often, it’s too early to say what the true impact of GenAI will be on the workforce – see other recent studies suggesting that productivity gains may (so far!) be overstated or marginal – but if it leads to doing more work at unsustainable rates, it would be a strange irony if the fears about job losses ultimately prove unfounded. Could GenAI end up pushing organisations to need more people, not fewer?
“You don’t know if you’re gonna get what you want on the first take or the 12th take or the 40th take”
This is GenAI’s current biggest challenge: It’s still being sold as primarily an efficiency tool – do more, faster!
In practice, as most who’ve played with it have found, it’s only faster if good enough is good enough. If you’re seeking excellence, it can help you to improve and refine what you’re doing – but not at speed.
The time / cost / quality pyramid persists, despite what we were all hoping.
What GenAI *is* allowing is for more people to try things that previously they’d never have been able to do – like code, write better, or create video or imagery.
But what this fascinating piece shows is that even genuine experts with a desire to experiment and push the boundaries can struggle to get genuinely excellent results – and that human + machine + time + iteration + patience remains (for now) the only way to get beyond good enough.
“These are nondeterministic, unpredictable systems that are now receiving inputs and context from other such systems… From a security perspective, it’s an absolute nightmare.”
The whole exercise initially struck me as a fun enough probabilistic parlour trick – similar to the entertaining “Infinite conversation” site with bots based on Werner Herzog and Slavoj Žižek from a couple of years back. There’s no true *intelligence* here, just chatbots slotting into established tropes for online forums, including creating their own memes and complaining about privacy and the mods (here, “the humans”).
So far so unsurprising – just as it’s unsurprising that some people who should know better have decided to read meaning and understanding into these interactions. (Hell, some of the stuff robot Werner Herzog came up with could also sound profound – it’s all in the voice…)
But what *is* new is the naiveté of some early adopters who’ve entrusted incredibly sensitive personal information and provided ridiculous amounts of access to AI agents whose programming is not deterministic and which are now able to interact with other agents.
The tech may be impressive – these agents are able to *do* more than I was expecting by this stage – but the potential for compound risk is insane. No sensible organisation would let a system like this anywhere near its operations until it’s possible to put far more robust constraints in place.
And so, just as with gambling, the question with GenAI systems seems increasingly to be all about personal and organisational risk tolerance.
My risk tolerance for this kind of thing is low, because the potential payoff – a bit of enhanced productivity? – is similarly low. If you’re really so time poor that you’re willing to take this gamble, then you need to rethink your priorities.
“While 82% of advertising executives believe Gen Z and millennial consumers feel positively about AI-generated ads, only 45% of these consumers actually feel that way”
But this is hardly a surprise. A couple of years back I referred to GenAI being at every stage of the Gartner hype cycle simultaneously, and that remains true today – it’s just that more people have passed over the peak of inflated expectations.
Meanwhile, the AI companies need to keep on trying to inflate those expectations further to keep the investment money coming in to allow them to build the infrastructure they need to keep delivering.
But we’re at a stage now where high level promises like those you get in an advert or keynote are hitting the law of diminishing returns. These companies are selling to an increasingly sceptical crowd – as a global society, we’re further down the funnel and are looking for more proof points before we buy in.
(This is part of why I’m convinced Elon Musk knew exactly what he was doing with his Grok porn bot – the uproar was great free publicity for Grok’s ability to create photorealistic images and video… PR can be cynical…)
Given this, is an old school Super bowl campaign really going to make any difference? or is this now just another old school brand awareness play, given Google seems to be on the verge of demolishing OpenAI’s previous lead?
Either way, we’re definitely entering a new phase in the AI play – and the emphasis is increasingly going to need to be on proof of impact, not just proof of concept. The narrative needs to shift.
At times I liked this a lot – a neat companion to Neal Stephenson’s Cryptonomicon as a novel about the birth of the computer age. It could equally work as a companion to Sebastian Mallaby’s non-fiction The Power Law, focused on the venture capitalists and somewhat unstable, potentially sociopathic tech bros who have built the modern tech industry into the morally suspect force that it is.
Effectively a montage rather than a narrative, with surprisingly little-known polymath genius John von Neumann and the various hugely influential ideas he had as its centre of gravity, it’s as wide-ranging as he was. This is the guy who co-created Game Theory (an approach many tech types seem to consciously adopt), helped develop not just the atomic bomb, but also the hydrogen bomb and concept of Mutually Assured Destruction – with its wonderfully appropriate acronym.
But he also came up with some initial concepts for artificial intelligence, notably the self-teaching, self-reproducing, self-improving Von Neumann machines that he envisioned spreading through the universe long after his (and humankind’s) death.
It’s this that the book is really building to throughout: Pretty much all modern AI systems are Von Neumann machines – at least, to an extent.
This makes this extremely timely and thought-provoking, despite being about someone who died 70 years ago.
How will these systems continue to evolve? Given von Neumann himself is, throughout, compared to the machines and systems he developed – his utterly alien way of thinking, his apparent disregard for his fellow humans, his neglect of his family, his apparent patronising contempt for people not as smart as he was – the suggestion that these alien intelligences are something to be wary and probably scared of starts coming through stronger and stronger.
This culminates in the final section, a detailed narrative of the significance and a blow by blow account of DeepMind’s 2016 victory over the world’s leading human Go player with their AlphaGo system.
Yet while an impressive achievement, as a whole the book didn’t quite work for me. The different voices talking about their relationships and experiences with von Neumann, done as if being interviewed, eventually all started to sound too similar. The opening and closing sections were thematically clearly linked, but the structure as a whole leaves the reader doing much of the work to connect the dots and get to the point the author’s making. A final coda to wrap it all up would, for me at least, have been appreciated.
If you’re happy with platitudinous banality for your “thought leadership”, GenAI is great!
The trouble is, this isn’t just a GenAI issue.
Many (most?) brands have been spewing out generic nonsense with their content marketing for as long as content marketing has been a thing.
Because what GenAI content is very good at exposing is something that those of us who’ve been working in content marketing for a long time have known since forever: Coming up with genuinely original, compelling insights is *incredibly* hard.
Especially when the raw material most B2B marketers have to work with is the half-remembered received wisdom a distracted senior stakeholder has just tried to recall from their MBA days in response to a question about their business strategy that they’ve probably never even considered before.
And even more especially when these days many of those senior stakeholders are asking their PA to ask ChatGPT to come up with an answer for the question via email rather than speak with anyone.
If you want real insight that’s going to impress real experts, you need to put the work in, and give it some real thought. GenAI can help with this – I have endless conversations with various bots to refine my thinking across dozens of projects. But even that takes time. Often a hell of a lot of time.
Because even in the age of GenAI, it turns out the project management Time / Cost / Quality triangle still applies.
We were having the same arguments 20 years ago about blog content from actual humans.
The problem is not with how the sausage is made but, as Sturgeon’s Law states, that “Ninety percent of everything is crap”.
(Of course, on Linkedin this quite simple – and surely obvious – statement led to lots of debate about the *ethics* of AI content rather than the quality. That’s a different matter altogether…)
“45% of the AI responses studied contained at least one significant issue, with 81% having some form of problem”
I’m a big fan of using GenAI to assist in research, ideation, and even sense-checking – asking it to help me with my own critical and lateral thinking. I use these tools multiple times a day, and am constantly encouraging the journalists I work with at Today Digital o use GenAI more to help them boost both their productivity and the impact of their work.
But it’s *vital* to keep fully aware of GenAI’s limitations when using it for anything where facts are important.
No matter how often we remind ourselves that LLMs have no true understanding, no real intelligence, no concept of what a “fact” actually is, the more you use them the easier it is to be taken in by their very, very convincing pastiche of true intelligence.
As this Reuters study shows, despite the apparent progress of the last couple of years, there are still fundamental challenges – which are unlikely to ever be fully overcome using this form of AI. (And which is why LLMs weren’t even classified as AI until very recently…)
The good news? With GenAI’s limitations increasingly becoming more widely appreciated, this could ultimately be a good thing for news orgs – because why go to an unreliable intermediary when you can go direct to the journalistic source?
Journalistic scepticism and fundamental critical thinking skills are becoming more important than ever.
The rhythms and tone of AI-assisted writing are now pretty much endemic on LinkedIn
And I get why: GenAI copy is generally pretty tight, pretty focused, and flows pretty well. Certainly better than most non-professional writers can manage on their own.
Hell, it sounds annoyingly like my own natural writing style, honed over years of practice…
But people I’ve known for years are starting to no longer sound like themselves.
Their words are too polished, too slick, too much like those an American social media copywriter would use, no matter where they’re from.
None of this post was written with AI.
And despite (because of?) being a professional writer/editor, It took me over half an hour of questioning myself, rewriting, starting again, looking for the right phrase. Doing this on my phone, my thumbs now ache and the little finger on my right hand, which I always use to support the weight while writing, is begging for a break.
With GenAI I could have “written” this in a fraction of the time, and it would have been tighter, easier to follow.
But it wouldn’t have been me – and I still (naively) want my social media interactions to be authentically human to human.
(Of course, the AI version would probably have ended up getting more engagement, because this post – as well as going out on a Sunday morning when no one’s looking, and without an image – is now far too long for most people, or the LinkedIn algorithm, to give it much attention. Hey ho!)
The question of what AI does to publishing has much more to do with why people are reading than how you wrote. Do they care who you are? About your voice or your story? Or are they looking for a database output? Benedict Evans, on LinkedIn
Context is (usually) more important to the success of content than the content itself. And that context depends on the reader/viewer/listener.
It’s the classic journalistic questioning model, but about the audience, not the story:
Who are they?
What are they looking for?
Why are they looking for it?
Where are they looking for it?
When do they need it by?
How else could they get the same results?
Which options will best meet their needs?
Every one of these questions impacts that individual’s perceptions of what type of content will be most valuable to them, and therefore their choice of preferred format / platform for that specific moment in time. Sometimes they’ll want a snappy overview, other times a deep dive, yet other times to hear direct from or talk with an expert.
GenAI enables format flexibility, and chatbot interfaces encourage audience interaction through follow-up Q&As that can help make answers increasingly specific and relevant. This means it will have some pretty wide applications – but it still won’t be appropriate to every context / audience need state.
The real question is which audience needs can publishers – and human content creators – meet better than GenAI?
It’s easy to criticise “AI slop” – but the internet has been awash with utterly bland, characterless human-created slop for years. If GenAI forces those of us in the media to try a bit harder, then it’s all for the good.
The GenAI equivalent of Googlebombing (remember that?) was one of my first concerns when pondering the likely impact of GenAI search, way back when ChatGPT 3.5 came out and the prospect started looking real.
This kind of thing is, sadly, inevitable. And while Google’s got very solid experience of getting around attempts to manipulate its algorithms, it doesn’t have a great track record of releasing AI products that can distinguish facts from confabulations (remember both the Bard and the Gemini launches?).
The other inevitability is that this is also going to lead to more scammy marketing techniques. We’re going to be inundated with yet more of those snake oil salespeople popping up to promise brands results in GenAI, just as they used to in the early days of SEO – fuelled by similar tactics of vast networks of websites all interlinking to each other to create the impression of authority.
Only now, rather than using underpaid humans in content farms, they’ll be using GenAI to spit out infinite copy and infinite webpages, poisoning the GenAI well for everyone in pursuit of short-term profits.
The last couple of years have seen far too many people who should know better simply regurgitate press releases without applying critical thinking – yet it’s the critical thinking that’s the increasingly essential “human in the loop” part of the equation.
And as familiarity breeds contempt, this kind of blunt, sceptical take on AI is likely to be increasingly common in 2025. Anyone – any organisation – wanting to be taken seriously is going to have to confront these kinds of questions honestly and openly if they’re going to be taken seriously.
But at the same time, it’s going to be important not to swing too far the other way – beyond inquisitiveness about the bold claims of the AI providers into outright cynicism.
It’s easy to shoot things down. It’s *extremely* easy to have a knee-jerk dislike of techbro hype trains when you lived through the Dotcom Crash. It’s much harder to dispassionately assess the merits of emerging technologies when they haven’t yet fully emerged.
As ever, a journalistic mindset can help:
Who‘s saying this? What are their creds? What’s in it for them? Do they have any financial stake?
What are they actually saying? Is there any substance, or is it filled with jargon and empty phrases? (It’s often surprising how little substance there is out there, given how much is being said…)
When did what they’re claiming first happen? Is this really new, or is it fresh spin on an old claim or capability? If a fresh spin, that’s not necessarily a bad thing – but why now?
Where‘s the evidence to support their claims? Can it be independently verified?
How does this claim differ to existing solutions? Is it really an improvement? What’s the cost vs benefit compared to alternatives?
Finally, as ever, try and get your info from more than one source. It’s tempting to only listen to people you agree with, and *very* tempting to dismiss anything coming from sources you dislike. But that leads to an incomplete picture – and a boring, predictable take.
And at a time where GenAI can spit out passable median opinion takes in seconds, what’s the point in reading anything boring and predictable?
Fascinating, if predictable, findings on ChatGPT source attribution, via TechCrunch – with significant implications for the emerging “Generative Engine Optimisation” successor to SEO that should concern anyone publishing online.
Short version – ChatGPT’s ability to provide accurate citations for the sources of its information remains extremely hit and miss, despite the rise of GenAI search:
“the fundamental issue is OpenAI’s technology is treating journalism ‘as decontextualized content’, with apparently little regard for the circumstances of its original production”
In other words, GenAI focuses on the substance, not the source. It doesn’t matter where a story / insight actually originated – only where the GenAI tool considers is most plausible for it to have originated.
This isn’t just a question of lost traffic due to the lack of a link – there are far more serious implications here.
For example, if you’re a corporate brand producing a big chunky piece of thought leadership based on months of research, this means you could find your work misattributed to a direct competitor if the GenAI algorithms decide a competitor is more likely to have produced something like this. Equally, someone else’s work – or opinion – may be attributed to you.
This is, of course, a potentially huge liability for any brand – especially as hostile actors could use this flaw in the way these tools work to game the system, similar to the old days of Googlebombing, and make it look like your brand has said something it hasn’t.
But it gets worse – there’s nothing* you can do about it:
“Nor does completely blocking crawlers mean publishers can save themselves from reputational damage risks by avoiding any mention of their stories in ChatGPT. The study found the bot still incorrectly attributed articles to the New York Times despite the ongoing lawsuit, for example.”
Welcome to the age of GenAI…
(* well, nothing guaranteed to work all the time, at least…)
To help shape my thinking, I write essays and shorter notes examining the ideas and narratives that shape media, marketing, technology and culture.
A core focus: The way context and assumptions can radically change how ideas are interpreted. Much of modern business, marketing, and media thinking is built on other people's frameworks, models, theories, and received wisdom. This can help clarify complex problems – but as ideas travel between disciplines and organisations they are often simplified, misapplied or treated as universal truths. I'm digging into these, across the following categories - the first being a catch-all for shorter thoughts:

 4/5 stars
4/5 stars Bad photo of a good slide on what makes content valuable in an AI era, from
Bad photo of a good slide on what makes content valuable in an AI era, from  I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?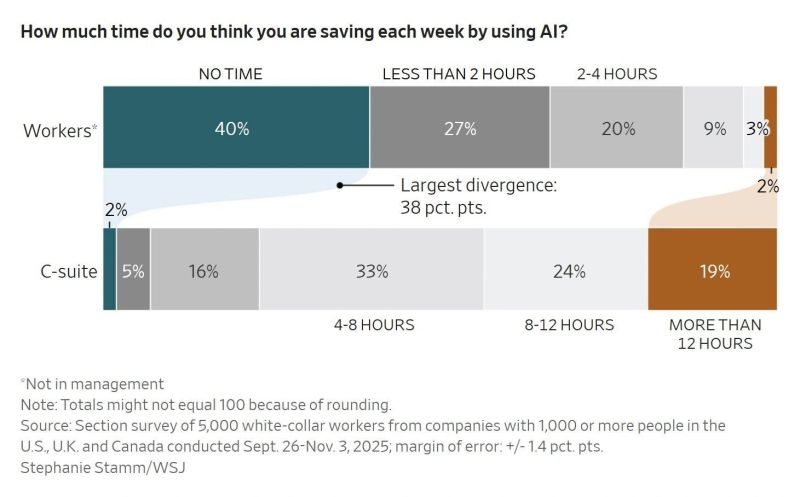

 GenAI content is neither good nor bad:
GenAI content is neither good nor bad: