by James Clive-Matthews | 10 Oct, 2025 | Systems & Technology
The rhythms and tone of AI-assisted writing are now pretty much endemic on LinkedIn
And I get why: GenAI copy is generally pretty tight, pretty focused, and flows pretty well. Certainly better than most non-professional writers can manage on their own.
Hell, it sounds annoyingly like my own natural writing style, honed over years of practice…
But people I’ve known for years are starting to no longer sound like themselves.
Their words are too polished, too slick, too much like those an American social media copywriter would use, no matter where they’re from.
None of this post was written with AI.
And despite (because of?) being a professional writer/editor, It took me over half an hour of questioning myself, rewriting, starting again, looking for the right phrase. Doing this on my phone, my thumbs now ache and the little finger on my right hand, which I always use to support the weight while writing, is begging for a break.
With GenAI I could have “written” this in a fraction of the time, and it would have been tighter, easier to follow.
But it wouldn’t have been me – and I still (naively) want my social media interactions to be authentically human to human.
(Of course, the AI version would probably have ended up getting more engagement, because this post – as well as going out on a Sunday morning when no one’s looking, and without an image – is now far too long for most people, or the LinkedIn algorithm, to give it much attention. Hey ho!)
by James Clive-Matthews | 24 Jul, 2025 | Systems & Technology
The Tragedy of the Commons is coming for the internet:
Google’s AI Is Destroying Search, the Internet, and Your Brain
404 Media, 23 July 2025
The GenAI equivalent of Googlebombing (remember that?) was one of my first concerns when pondering the likely impact of GenAI search, way back when ChatGPT 3.5 came out and the prospect started looking real.
This kind of thing is, sadly, inevitable. And while Google’s got very solid experience of getting around attempts to manipulate its algorithms, it doesn’t have a great track record of releasing AI products that can distinguish facts from confabulations (remember both the Bard and the Gemini launches?).
The other inevitability is that this is also going to lead to more scammy marketing techniques. We’re going to be inundated with yet more of those snake oil salespeople popping up to promise brands results in GenAI, just as they used to in the early days of SEO – fuelled by similar tactics of vast networks of websites all interlinking to each other to create the impression of authority.
Only now, rather than using underpaid humans in content farms, they’ll be using GenAI to spit out infinite copy and infinite webpages, poisoning the GenAI well for everyone in pursuit of short-term profits.
by James Clive-Matthews | 30 Nov, 2024 | Systems & Technology
Fascinating, if predictable, findings on ChatGPT source attribution, via TechCrunch – with significant implications for the emerging “Generative Engine Optimisation” successor to SEO that should concern anyone publishing online.
Short version – ChatGPT’s ability to provide accurate citations for the sources of its information remains extremely hit and miss, despite the rise of GenAI search:
“the fundamental issue is OpenAI’s technology is treating journalism ‘as decontextualized content’, with apparently little regard for the circumstances of its original production”
In other words, GenAI focuses on the substance, not the source. It doesn’t matter where a story / insight actually originated – only where the GenAI tool considers is most plausible for it to have originated.
This isn’t just a question of lost traffic due to the lack of a link – there are far more serious implications here.
For example, if you’re a corporate brand producing a big chunky piece of thought leadership based on months of research, this means you could find your work misattributed to a direct competitor if the GenAI algorithms decide a competitor is more likely to have produced something like this. Equally, someone else’s work – or opinion – may be attributed to you.
This is, of course, a potentially huge liability for any brand – especially as hostile actors could use this flaw in the way these tools work to game the system, similar to the old days of Googlebombing, and make it look like your brand has said something it hasn’t.
But it gets worse – there’s nothing* you can do about it:
“Nor does completely blocking crawlers mean publishers can save themselves from reputational damage risks by avoiding any mention of their stories in ChatGPT. The study found the bot still incorrectly attributed articles to the New York Times despite the ongoing lawsuit, for example.”
Welcome to the age of GenAI…
(* well, nothing guaranteed to work all the time, at least…)
by James Clive-Matthews | 21 Aug, 2024 | Systems & Technology
 The default writing style of GenAI is becoming ever more prevalent on LinkedIn, both in posts and comments.
The default writing style of GenAI is becoming ever more prevalent on LinkedIn, both in posts and comments.
This GenAI standard copy has a rhythm that, because it’s becoming so common, is becoming increasingly noticeable.
Sometimes it’s really very obvious we’ve got bots talking to bots – especially on those AI-generated posts where LinkedIn tries to algorithmically flatter us by pretending we’re one of a select few experts invited to respond to a question.
—
Top tip: If you’re using LinkedIn to build a personal / professional brand, you really need a personality – a style or tone (and preferably ideas) of your own. If you sound the same as everyone else, you fade into the background noise.
So while it may be tempting to hit the “Rewrite with AI” button, or just paste a question into your Chatbot of choice, my advice: Don’t.
Or, at least, don’t without giving it some thought.
—
There are lots of good reasons to use AI to help with your writing – it’s an annoyingly good editor when used carefully, and can be a superb help for people working in their second language, or with neurodiverse needs. It can be helpful to spot ways to tighten arguments, and in suggesting additional points. But like any tool, it needs a bit of practice and skill to use well.
But seeing that this platform is about showing off professional skills, don’t use the default – that’s like turning up to a client presentation with a PowerPoint with no formatting.
Put a bit of effort in, and maybe you’ll get read and responded to by people, not just bots. And isn’t that the point of *social* media?
by James Clive-Matthews | 15 Aug, 2024 | Systems & Technology
There’s some fascinating stuff in this SEO long read, based on impressive research and analysis. Just bear in mind that, as leaked Google documents put it, “If you think you understand how [search algorithms] work, trust us: you don’t. We’re not sure that we do either.”
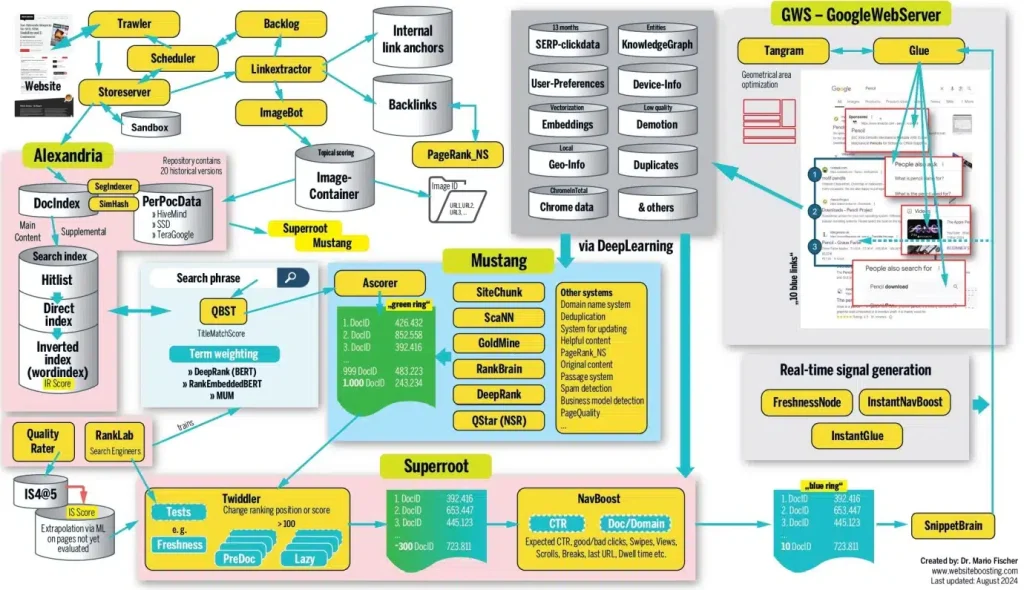 To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
For me, this all confirms a few core content principles:
- Context is king, not content. You can have an amazing page full of astounding insight, but if it doesn’t clearly meet the needs of the user at that moment in time, it will go unviewed.
- Page structure is at least as important as substance – if (human and bot) audiences can’t quickly tell that your page is interesting and relevant, they’ll bounce.
- But don’t worry – the key to success is rarely going to be a single webpage. More important is the authority of the domain and brand.
- This means the impact of content is at least as much about cumulative brand building as it is immediate engagement. Think of the long tail, not just the short spike – and focus your content strategy on building this long-term growth over the short-term quick hit.
- Given so much about how this works is unknown, and so many factors are outside your control, it’s best not to over-think it. Follow all the advice SEO experts offer, and you’ll end up with something so over-engineered it’ll lose its coherence and flow. This will increase bounce rates.
So how to succeed?
Go back to basics: Focus on ensuring your content fulfills a clear audience need (ideally currently unmet by other sources), using language audiences are looking for, presented in ways audiences are likely to engage with, and with clear links to and from other relevant content to help both humans and bots understand its relevance within the broader context.
In other words, SEO may be complex when you dig into the details – but it’s really just a combination of common sense, long-term authority building, and a good bit of luck.
It’s still worth reading the whole thing, though.
by James Clive-Matthews | 5 Aug, 2024 | Systems & Technology
 Given the music industry’s track record of building successful cases for unauthorised sampling and even inadvertent plagiarism (aka Cryptomnesia, as with the George Harrison ‘My Sweet Lord’ lawsuit back in the 70s) this will be the one to watch.
Given the music industry’s track record of building successful cases for unauthorised sampling and even inadvertent plagiarism (aka Cryptomnesia, as with the George Harrison ‘My Sweet Lord’ lawsuit back in the 70s) this will be the one to watch.
The music industry’s absolutist approach to copyright is a dangerous path to follow, however. How can you legally define the difference between “taking inspiration from” and “imitating”? What’s the difference between a GenAI tool creating music in the style of an artist, and an artist operating within a genre tradition?
*Everything* is a mashup or a reference, to a greater or lesser extent – that’s how culture works. We’re all standing on the shoulders of giants – as well as myriad lesser influences, most of which are subconscious. Hell, the saying “there’s nothing new under the sun” comes from the Book of Ecclesiastes, written well over 2,000 years ago.
Put legal restrictions on the right of anyone – human or bot – to build or riff on what’s come before, and culture risks hitting a dead end.
So while I have sympathy with artists’ concerns, the claim that GenAI could “sabotage creativity” is a nonsense in the same way claims that the printing press or photocopier could sabotage creativity are. Creativity is about the combination of ideas and influences and continual experimentation to find out what works – GenAI can help us all do this faster than ever. If anything, this should help increase creativity.
What *does* sabotage creativity is short-termist, protectionist restrictions on who’s allowed to do what – exactly like the ones these lawsuits are trying to impose.
by James Clive-Matthews | 1 Aug, 2024 | Systems & Technology
 “When AI is mentioned, it tends to lower emotional trust, which in turn decreases purchase intentions.”
“When AI is mentioned, it tends to lower emotional trust, which in turn decreases purchase intentions.”
An interesting finding, this – especially as it transcends product and service categories – though perhaps to be expected at this stage of the GenAI hype cycle.
This kind of scepticism isn’t easy to overcome – with new technologies acceptance and mass adoption is often a matter of time – but as the authors of the study point out, the key issue to address is the lack of trust in AI as a technology.
Some of this lack of trust is due to lack of familiarity – natural language GenAI seems intuitive, but actually takes a lot of practice to get decent results.
Some will be due to the opposite – follow the likes of Gary Marcus, and it’s hard not to get sceptical about the sustainability, benefits, and reliability of the current approach to GenAI.
The danger, though, is that this scepticism may be spreading to AI as a whole. The prominence of GenAI in the current AI discourse is leading to different types of artificial intelligence becoming conflated in the popular imagination – even though, just a few years ago, the form of machine learning we now call GenAI wouldn’t even have been classified as artificial intelligence.
Tech terms can rapidly become toxic – think “web3”, “NFT”, and “metaverse”. Could GenAI be starting to experience a similar branding problem? And could this damage perception of other kinds of AI in the process?
by James Clive-Matthews | 1 Aug, 2024 | Systems & Technology
 The decline in news audiences reported here – 43%, or 11 million daily views – is shockingly high. This follows Canada’s ill-considered battle with Meta, which led to Meta pulling news from its platforms, including Facebook, in the Canadian market last year, rather than arrange content licensing agreements with news publishers.
The decline in news audiences reported here – 43%, or 11 million daily views – is shockingly high. This follows Canada’s ill-considered battle with Meta, which led to Meta pulling news from its platforms, including Facebook, in the Canadian market last year, rather than arrange content licensing agreements with news publishers.
This amply demonstrates the vast power these tech platforms have in society and over the media industry, and so justifies the Canadian government’s worries. But it also more than shows – once again – how utterly dependent the online content ecosystem is on these channels for distribution.
Meta/Facebook obviously isn’t a monopoly, but a 43% decline in news consumption thanks to the shutting down of one set of distribution channels? It’s a safe bet that much of the rest of the traffic will be from Google, so it’s more of a duopoly.
What impact is this level of reliance on a couple of gatekeeping tech platforms – who can change their policies on a whim at any time – going to have on public awareness of current events and society at large
Elsewhere in the article we have an answer: “just 22 per cent of Canadians are aware a ban is in place”.
Shut down access to news, little wonder that awareness of news stories stays low.
Both Canada (with Meta) and Australia (with Google and Meta) have tried forcing the tech giants into doing licensing deals for content that their platforms promote. In both cases, this has – predictably – backfired, and led to the opposite effect to that intended.
But what’s the solution?
This question is becoming more urgent now that GenAI is in the mix, and starting to provide summaries of stories rather than just provide a headline, image, and link.
Meta/Google were effectively acting like a newsstand – showing passing punters a range of headlines to attract their attention and pull in an audience.
GenAI’s summarisation approach, meanwhile, is much closer to what Meta and Google were being (unfairly) accused of doing by the Canadian and Australian governments: Taking traffic away from news sites by providing an overview of the story on their own platforms.
But the GenAI Pandora’s Box has already been opened. Publishers need to move away from wishful thinking – the main cause of the failed Australian/Canadian experiments – and back to harsh reality.
Unlike the Meta news withdrawal – which could be reversed – this new threat to content distribution models isn’t going away.
by James Clive-Matthews | 31 Jul, 2024 | Systems & Technology
 “If your website is referenced in a Perplexity search result where the company earns advertising revenue, you’ll be eligible for revenue share.”
“If your website is referenced in a Perplexity search result where the company earns advertising revenue, you’ll be eligible for revenue share.”
How many qualifiers can be fitted into one sentence, all while providing next to no information?
To be clear, I’ve loved WordPress ever since I migrated my old blog to it [checks archives] *18* years ago [damn…] I also fully get why they’re doing this – some money is better than none, it may work out, and it may actually lead to more traffic / engagement / visibility for WordPress sites.
But this all feels a little like promises of scraps falling from the table of people who are getting scraps falling from an even higher table.
Perplexity currently claims to be making US$20 million from paid subscriptions to its pro service – about the only source of income it currently seems to have, despite its $2.5-3 billion valuation. If they’re now giving away some of that limited income, I can’t see an obvious path to profitability, given the hefty running costs of GenAI.
This doesn’t just go for Perplexity, but for all these GenAI tools:
- What’s the path to a sustainable content publishing-based business model (and all these GenAI companies are content companies) when being able to produce infinite content on demand means the traditional route for making money for these kinds of companies – advertising inventory – is also infinite?
- Value comes from scarcity. Content / as inventory is no longer scarce. How do you make something that’s not scarce seem valuable enough to get people to pay for it?
- And when all GenAI models offer more or less the same output, and more or less the same level of reliability, and successful features and approaches can be replicated by the competition in next to no time, how do you stand out from the crowd?
Being a content/tech geek I’ve been thinking about this a lot over the last couple of years. Perplexity’s approach is one I like (I did history at university, so I love a good list of sources, even if they’ve mostly just been added to make your work look more credible and most of them are irrelevant, as is often the case with Perplexity) – but I’m far from convinced it has money-making potential. As Wired has put it, Perplexity is a bullshit machine. How valuable is bullshit?
Basically, we’re firmly in the destruction phase of creative destruction. The creative part is yet to come
But still – at least the providers of the raw material these LLMs are so reliant on are starting to get thrown a few bones. That’s a step in the right direction – because as that recent Nature study made clear, the proliferation of AI-generated content risks surprisingly rapid synthetic data-induced model collapse.
Human-created content may no longer be king, but it remains vitally important. Without it – and a hefty dose of critical thinking – the whole system comes tumbling down.
by James Clive-Matthews | 12 Mar, 2021 | Systems & Technology
As the FT points out, big tech has so much data on us, surely ad targeting should be good by now?
The real solution to increasing your chances of reaching the right people isn’t marketing automation, it’s user experience. One’s a tactic, the other’s a strategy.
After all, if even Facebook struggles to identify audience interests with any degree of accuracy, what hope do more limited platforms have?
The risk isn’t just that you’re wasting your paid media spend on micro-targeting, it’s that you’re wasting your production budget producing multiple variants of marketing content for audiences that may never see your material. It’s lose-lose.
The magic bullet isn’t audience segmentation in promotion plans – it’s focusing on your audiences’ interests in the content and messaging development phase. This helps ensure what you’re saying (and how you’re saying it) can appeal to multiple target groups at the same time – from niche to broad. Then you can let your audiences self-select the next step on their customer journey via clear signposting of where to go to find what they want.
One size may not fit all perfectly, but with a skilled tailor one size can be given the *illusion* of fitting all. People will pay attention to the things they’re interested in, not the things they aren’t. Which makes people far more capable of deciding what’s relevant to them than any algorithm.
