by James Clive-Matthews | 1 Apr, 2026 | Systems & Technology |
 Bad photo of a good slide on what makes content valuable in an AI era, from Kevin Anderson at the inaugural Source Code event last night.
Bad photo of a good slide on what makes content valuable in an AI era, from Kevin Anderson at the inaugural Source Code event last night.
A successor to the much missed Hack/Hackers series looking at how tech and journalism can come together to do great things, it was unsurprisingly dominated by conversations about AI.
The point about what is valuable about the content we produce was also core to my old colleague Steven Wilson-Beales‘ session on SEO / GEO / AEO / AIO / whatever you want to call it, and what a “zero click” web could look like in practice.
Key points:
– You need differentiation
– You need to add value
– You need to be accessible, relevant, and credible
It’s almost as if E-E-A-T is still a thing!
Also, the lesson we should all have taken from the last decade and a bit of chasing search and social algorithms is simple – diversify.
Don’t get over reliant on any one traffic source. Don’t chase the algorithm, because the algorithm is changing faster than ever – and with AI search, will increasingly adapt it’s findings to every individual.
And a top tip – given AI tools have been trained on existing content, you need to take a careful look at your archives. If they don’t answer the potential needs of an AI bot in query fan out mode, they may need an update.
—
But the absolute key point – and this speaks to a lot of the work I’ve been doing behind the scenes lately – It’s no longer enough to focus your SEO / GEO efforts on optimisation of individual pages.
You need to see your content as part of a broader system – because the bots are no longer looking for just one page to rank at the top of a list, they’re looking for the right information to answer the query. If they can’t get it from you, they’ll get it from someone else. (Or just make it up…)
by James Clive-Matthews | 19 Mar, 2026 | Structures & Models
 I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
These systems don’t just read what you publish and serve up the most relevant parts – they synthesise it, blending multiple sources based on patterns they infer across a wider field of signals:
– everything you publish
– everything others publish about you
– everything they consider adjacent or comparable
They’re also not just looking at what’s being said now. They’re conflating and combining the accumulated traces of how your organisation expresses itself over time – across campaigns, content, product information and everything in between.
Repetition and consistency may help, but they won’t just pick up what you intend. They absorb whatever is most legible – including contradictions, gaps, and overlap with competitors.
If your positioning isn’t distinctive, you’ll get flattened into the category. If your communication isn’t coherent, the model will reconstruct a version of your brand from whatever patterns it can find. And when it comes to facts and details – where accuracy actually matters – these systems are still unreliable enough to pose a real risk.
This is where a focus on structured data starts to look like a promising way forward. That was my first assumption. But it’s becoming increasingly clear that this isn’t going to be enough.
—
The key is to remember that these systems don’t *understand* information. They generate outputs by following probabilistic sequences – patterns shaped by the data they’ve seen.
It’s a sophistiated form of word association. Structure helps, but only where it clarifies those patterns to nudge the model to follow the path you’d prefer.
Over time, what you’re really creating – deliberately or not – is a set of associations the LLM learns to treat as related. What we’d normally think of as a brand “narrative” sits inside that – not as something the model understands directly, but as a pattern of connections it learns to reproduce.
—
This means “AEO” should be considered less about optimising individual outputs, and more about the long-term shape of the signals you generate – across teams, markets and years.
I’ve been doing some work on this recently, trying to make that problem more tangible and diagnosable in practice. Still early, but the direction of travel feels clearer.
The brands that show up well won’t just be the ones optimising for visibility. They’ll be the ones whose overall pattern of behaviour is coherent enough that even a probabilistic system can’t easily misread what they are.
by James Clive-Matthews | 25 Feb, 2026 | Marginalia
Most of what the “GEO” crowd are peddling now *sounds* logical with all its talk of structured data and query fan outs, and is more or less exactly what I was arguing back in late 2023 / early 2024.
I was wrong then, and they’re still wrong now. As Orange Labs founder Britney Muller puts it:
During training, LLMs process text from across the web, but they don’t log URLs, store sources, or remember where anything came from. What’s left is a frozen statistical snapshot (Gao et al., 2023). Not an index. Not a database.
Search engines do the crawling, indexing, and retrieval. LLMs lean on them heavily to surface real-time info (because on their own, they can’t).
Stop optimizing for ‘AI.’ Optimize for search engines (so retrieval-based AI can cite you) + earn third-party coverage (so the model already knows you before the prompt is typed).
That’s not to say query fan out logic (and other “GEO” tactics) doesn’t have its place in content planning – it does. But all this *really* is is a fancy name for an FAQ page (with less emphasis on the “F”). That’s been a core idea in SEO for over two decades. And pretty much all the rest of the “GEO” advice is similarly reskinned old school SEO – from keyword stuffing to linkfarm spamdexing – that Google quietly filtered out years ago.
There’s an awful lot of snake oil being flogged out there at the moment. If some of it seems to work, it’s more by accident than design.
by James Clive-Matthews | 11 Feb, 2026 | Systems & Technology
This is a nice, neat summary of the core constraints of current LLM based AI when it comes to SEO/GEO (based on a much longer, more technical piece, if you want the details).
Back when ChatGPT 3.5 came out, I was telling anyone who’d listen that it was going to disrupt search and publishing.
In early 2024, while at PwC, I started pitching new content formats to address this – intended to help capture whatever the GenAI equivalent of search ranking was going to be. “GEO” before this label stuck (I was calling it AIO at the time).
My thinking then was based on what seemed to be a logical, structured approach – similar to the “query fan out” advocates you’ll see in the “GEO” space today. (Basically label the hell out of your content, anticipate and answer the questions your target audience is likely to ask, as that structure should help the AI understand the context more easily, and so encourage it to pull from your page rather than someone else’s. Effectively a slightly deeper version of an old school Q&A or FAQ piece…)
But as I dug deeper it soon became clear that the challenge with LLM-based GenAI (from a model visibility perspective) wasn’t to do with clarifying the intended meaning of the information you want the model to ingest and regurgitate, as I first thought. (“These things can process unstructured data, but they’ll process *structured* data easier – so let’s structure it for them.”)
Instead it’s that these systems – despite being called Large *Language* Models – don’t actually understand language, or context. “Logic” to them is a meaningless concept; not only that, they have no concept of what a concept even is.
—
Tokens aren’t words, and don’t have meaning independently – they only appear to have meaning when combined into words.
Tokens create the illusion of being words (and having meaning) because of the probabilistic nature of these tools, when working with them using language as the system interface. This creates an environment in which they’re working within the rules of language, so can produce output that makes sense – even if they don’t “understand” what they’re saying.
But URLs aren’t language, and don’t have linguistic rules or any consistency from site to site in terms of information architecture. Every site’s URL structure is similar, but different.
And as LLMs don’t really understand structure (except as recognisable, predictable patterns), this makes accurately relating URLs a significant challenge for current LLM-based GenAI tools.
—
This is a structural challenge, baked into the very nature of these models. Despite what many GEO “experts” are now claiming, if your goal is to generate links and traffic from GenAI results, it’s not going to be an easy one to engineer if you’re working from outside that system.
It may be possible to tweak model outputs to improve this and increase URL attribution accuracy, but a) it won’t remove the underlying structural constraints, and b) what would be the incentive for the GenAI companies to do this?
The dust has yet to settle on this one.
by James Clive-Matthews | 24 Jul, 2025 | Systems & Technology
The Tragedy of the Commons is coming for the internet:
Google’s AI Is Destroying Search, the Internet, and Your Brain
404 Media, 23 July 2025
The GenAI equivalent of Googlebombing (remember that?) was one of my first concerns when pondering the likely impact of GenAI search, way back when ChatGPT 3.5 came out and the prospect started looking real.
This kind of thing is, sadly, inevitable. And while Google’s got very solid experience of getting around attempts to manipulate its algorithms, it doesn’t have a great track record of releasing AI products that can distinguish facts from confabulations (remember both the Bard and the Gemini launches?).
The other inevitability is that this is also going to lead to more scammy marketing techniques. We’re going to be inundated with yet more of those snake oil salespeople popping up to promise brands results in GenAI, just as they used to in the early days of SEO – fuelled by similar tactics of vast networks of websites all interlinking to each other to create the impression of authority.
Only now, rather than using underpaid humans in content farms, they’ll be using GenAI to spit out infinite copy and infinite webpages, poisoning the GenAI well for everyone in pursuit of short-term profits.
by James Clive-Matthews | 30 Nov, 2024 | Systems & Technology
Fascinating, if predictable, findings on ChatGPT source attribution, via TechCrunch – with significant implications for the emerging “Generative Engine Optimisation” successor to SEO that should concern anyone publishing online.
Short version – ChatGPT’s ability to provide accurate citations for the sources of its information remains extremely hit and miss, despite the rise of GenAI search:
“the fundamental issue is OpenAI’s technology is treating journalism ‘as decontextualized content’, with apparently little regard for the circumstances of its original production”
In other words, GenAI focuses on the substance, not the source. It doesn’t matter where a story / insight actually originated – only where the GenAI tool considers is most plausible for it to have originated.
This isn’t just a question of lost traffic due to the lack of a link – there are far more serious implications here.
For example, if you’re a corporate brand producing a big chunky piece of thought leadership based on months of research, this means you could find your work misattributed to a direct competitor if the GenAI algorithms decide a competitor is more likely to have produced something like this. Equally, someone else’s work – or opinion – may be attributed to you.
This is, of course, a potentially huge liability for any brand – especially as hostile actors could use this flaw in the way these tools work to game the system, similar to the old days of Googlebombing, and make it look like your brand has said something it hasn’t.
But it gets worse – there’s nothing* you can do about it:
“Nor does completely blocking crawlers mean publishers can save themselves from reputational damage risks by avoiding any mention of their stories in ChatGPT. The study found the bot still incorrectly attributed articles to the New York Times despite the ongoing lawsuit, for example.”
Welcome to the age of GenAI…
(* well, nothing guaranteed to work all the time, at least…)
by James Clive-Matthews | 15 Aug, 2024 | Systems & Technology
There’s some fascinating stuff in this SEO long read, based on impressive research and analysis. Just bear in mind that, as leaked Google documents put it, “If you think you understand how [search algorithms] work, trust us: you don’t. We’re not sure that we do either.”
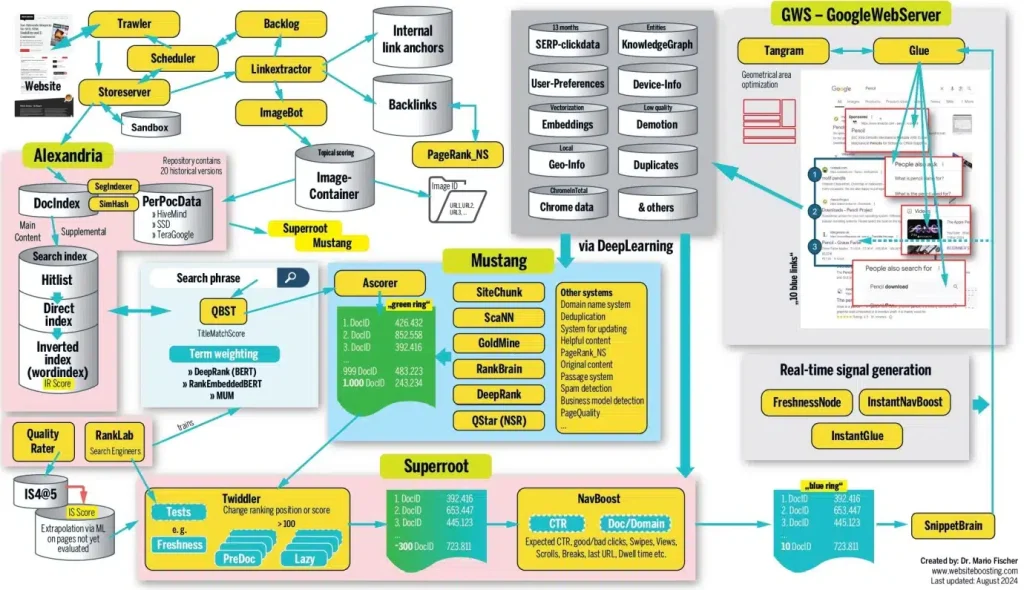 To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
For me, this all confirms a few core content principles:
- Context is king, not content. You can have an amazing page full of astounding insight, but if it doesn’t clearly meet the needs of the user at that moment in time, it will go unviewed.
- Page structure is at least as important as substance – if (human and bot) audiences can’t quickly tell that your page is interesting and relevant, they’ll bounce.
- But don’t worry – the key to success is rarely going to be a single webpage. More important is the authority of the domain and brand.
- This means the impact of content is at least as much about cumulative brand building as it is immediate engagement. Think of the long tail, not just the short spike – and focus your content strategy on building this long-term growth over the short-term quick hit.
- Given so much about how this works is unknown, and so many factors are outside your control, it’s best not to over-think it. Follow all the advice SEO experts offer, and you’ll end up with something so over-engineered it’ll lose its coherence and flow. This will increase bounce rates.
So how to succeed?
Go back to basics: Focus on ensuring your content fulfills a clear audience need (ideally currently unmet by other sources), using language audiences are looking for, presented in ways audiences are likely to engage with, and with clear links to and from other relevant content to help both humans and bots understand its relevance within the broader context.
In other words, SEO may be complex when you dig into the details – but it’s really just a combination of common sense, long-term authority building, and a good bit of luck.
It’s still worth reading the whole thing, though.
by James Clive-Matthews | 7 May, 2020 | Systems & Technology
“I haven’t witnessed an update as widespread as this one since 2003,” says the author of this piece. Some sites are reporting 90% traffic drops, with even the likes of Spotify and LinkedIn apparently impacted. This is big.
What exactly has changed is still unclear – a few days on results are still fluctuating too much for detailed analysis – but one thing does seem certain: “there are multiple reports of thin content losing positions”.
This has been the trend with Google for a while now, with the firm recommending “focusing on ensuring you’re offering the best content you can. That’s what our algorithms seek to reward.”
What *is* good content in this context? After all, “quality” is quite a subjective concept.
Well, algorithms aren’t people, but Google’s long been aiming to make their code more intelligent, and better able to understand context and likely relevance. Keyword stuffing has been penalised for years, as have dodgy link-building efforts. Instead, Google is aiming for near-human levels of appreciation of nuance.
Helpfully, though, Google has also put out a list of questions to help you understand if the content of your site is likely to be seen as quality in the eyes of the all-powerful algorithm:
- Does the content provide original information, reporting, research or analysis?
- Does the content provide a substantial, complete or comprehensive description of the topic?
- Does the content provide insightful analysis or interesting information that is beyond obvious?
- If the content draws on other sources, does it avoid simply copying or rewriting those sources and instead provide substantial additional value and originality?
- Does the headline and/or page title provide a descriptive, helpful summary of the content?
- Does the headline and/or page title avoid being exaggerating or shocking in nature?
All good questions, and all from Google’s own blog.
by James Clive-Matthews | 29 Aug, 2014 | Marginalia
*cue thousands of SEO experts desperately trying to work out what this means*
by James Clive-Matthews | 10 Jun, 2014 | Marginalia
Some great charts here – the overhype of social has been increasingly grating in recent years, a repeat of the 2003-5 excitement over blogging as the future of everything journalism, or the great SEO craze of approximately the same period, where the right combination of metadata and keywords were seen as some kind of magic bullet that could take any site to the top of the first page of Google.
Thankfully, everyone’s woken up to the limitations of both blogging and SEO. We’re now hopefully now coming to the same realisation with social, with more and more myths about clicks, engagement, sales, and all sorts being shattered left, right and centre.
But what we really need is the backlash to the backlash will hopefully follow soon after. Because although neither blogging nor SEO were quite the massive game changers they were made out to be, both have had (and continue to have) a huge positive impact on both the online world and the media as a whole. We simply now have a better understanding of their limitations as well as their strengths – which puts us in a much stronger position. Add the same rational approach to social (an approach that anyone with a Twitter addiction as bad as mine could have told you about years ago), and we should end up stronger yet again.
by James Clive-Matthews | 23 May, 2014 | Systems & Technology
Another Google algo update and, as ever, original, interesting, useful content is key to SEO success.
The hit eBay’s taken is interesting, though… An 80% drop in Google traffic coukd be a business-killer for anyone less big. And their content surely *is* original and relevant, what with the products changing all the time?
Possibly another impact from the authorship/Google+ changes the Google guys have introduced? After all, eBay product page writers are hardly likely to be verified Google+ authors. Is this why eBay are starting to invest in creating narrative content around their auctions?
Update: See also the ever-excellent Matthew Ingram on this, who points out the extremely worrying hit the long-running and much-loved Metafilter has taken:
“Reliant on Google not only for the bulk of its traffic but also the bulk of its advertising revenue, Metafilter has had to lay off almost half of its staff.”
The lesson?
Google can kill a site on a whim, and even the experts can’t tell us how or why, because Google’s algorithms are even more secret than the Colonel’s delicious blend of herbs and spices. Any site dependent on search for the bulk of its traffic is playing a very, very dangerous game.
Update 2: More detail on the Metafilter revenue/traffic decline, complete with stats.
The related power of Facebook to stifle updates from sources it has deemed to be suspect for whatever reason simply – and even the New York Times’ recently-leaked innovation report’s charts In the decline of its homepage – makes an obvious cliché all the more true even it comes to Web traffic: don’t put all your eggs in one basket.
If more than 25% of your traffic/revenue comes from one source, you’re in danger. More than 50%, you have a potential death sentence. All it takes is one thing to change, and you’re screwed.
