by JCM | 15 Aug, 2024 | Systems & Technology
There’s some fascinating stuff in this SEO long read, based on impressive research and analysis. Just bear in mind that, as leaked Google documents put it, “If you think you understand how [search algorithms] work, trust us: you don’t. We’re not sure that we do either.”
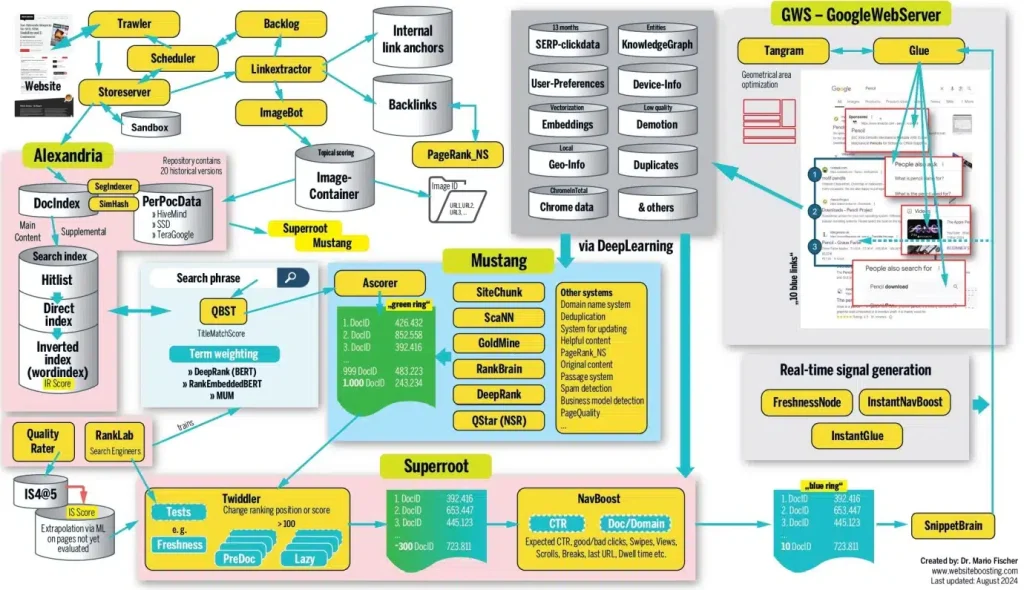 To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
To save you time, the main lesson is that “achieving a high ranking isn’t solely about having a great document or implementing the right SEO measures with high-quality content”. Search results shift in near realtime based on thousands of utterly opaque, interconnected assessments of obscure demand and user intent signals, so there’s only so much website managers can do.
For me, this all confirms a few core content principles:
- Context is king, not content. You can have an amazing page full of astounding insight, but if it doesn’t clearly meet the needs of the user at that moment in time, it will go unviewed.
- Page structure is at least as important as substance – if (human and bot) audiences can’t quickly tell that your page is interesting and relevant, they’ll bounce.
- But don’t worry – the key to success is rarely going to be a single webpage. More important is the authority of the domain and brand.
- This means the impact of content is at least as much about cumulative brand building as it is immediate engagement. Think of the long tail, not just the short spike – and focus your content strategy on building this long-term growth over the short-term quick hit.
- Given so much about how this works is unknown, and so many factors are outside your control, it’s best not to over-think it. Follow all the advice SEO experts offer, and you’ll end up with something so over-engineered it’ll lose its coherence and flow. This will increase bounce rates.
So how to succeed?
Go back to basics: Focus on ensuring your content fulfills a clear audience need (ideally currently unmet by other sources), using language audiences are looking for, presented in ways audiences are likely to engage with, and with clear links to and from other relevant content to help both humans and bots understand its relevance within the broader context.
In other words, SEO may be complex when you dig into the details – but it’s really just a combination of common sense, long-term authority building, and a good bit of luck.
It’s still worth reading the whole thing, though.
by JCM | 5 Aug, 2024 | Systems & Technology
 Given the music industry’s track record of building successful cases for unauthorised sampling and even inadvertent plagiarism (aka Cryptomnesia, as with the George Harrison ‘My Sweet Lord’ lawsuit back in the 70s) this will be the one to watch.
Given the music industry’s track record of building successful cases for unauthorised sampling and even inadvertent plagiarism (aka Cryptomnesia, as with the George Harrison ‘My Sweet Lord’ lawsuit back in the 70s) this will be the one to watch.
The music industry’s absolutist approach to copyright is a dangerous path to follow, however. How can you legally define the difference between “taking inspiration from” and “imitating”? What’s the difference between a GenAI tool creating music in the style of an artist, and an artist operating within a genre tradition?
*Everything* is a mashup or a reference, to a greater or lesser extent – that’s how culture works. We’re all standing on the shoulders of giants – as well as myriad lesser influences, most of which are subconscious. Hell, the saying “there’s nothing new under the sun” comes from the Book of Ecclesiastes, written well over 2,000 years ago.
Put legal restrictions on the right of anyone – human or bot – to build or riff on what’s come before, and culture risks hitting a dead end.
So while I have sympathy with artists’ concerns, the claim that GenAI could “sabotage creativity” is a nonsense in the same way claims that the printing press or photocopier could sabotage creativity are. Creativity is about the combination of ideas and influences and continual experimentation to find out what works – GenAI can help us all do this faster than ever. If anything, this should help increase creativity.
What *does* sabotage creativity is short-termist, protectionist restrictions on who’s allowed to do what – exactly like the ones these lawsuits are trying to impose.
by JCM | 1 Aug, 2024 | Systems & Technology
 “When AI is mentioned, it tends to lower emotional trust, which in turn decreases purchase intentions.”
“When AI is mentioned, it tends to lower emotional trust, which in turn decreases purchase intentions.”
An interesting finding, this – especially as it transcends product and service categories – though perhaps to be expected at this stage of the GenAI hype cycle.
This kind of scepticism isn’t easy to overcome – with new technologies acceptance and mass adoption is often a matter of time – but as the authors of the study point out, the key issue to address is the lack of trust in AI as a technology.
Some of this lack of trust is due to lack of familiarity – natural language GenAI seems intuitive, but actually takes a lot of practice to get decent results.
Some will be due to the opposite – follow the likes of Gary Marcus, and it’s hard not to get sceptical about the sustainability, benefits, and reliability of the current approach to GenAI.
The danger, though, is that this scepticism may be spreading to AI as a whole. The prominence of GenAI in the current AI discourse is leading to different types of artificial intelligence becoming conflated in the popular imagination – even though, just a few years ago, the form of machine learning we now call GenAI wouldn’t even have been classified as artificial intelligence.
Tech terms can rapidly become toxic – think “web3”, “NFT”, and “metaverse”. Could GenAI be starting to experience a similar branding problem? And could this damage perception of other kinds of AI in the process?
by JCM | 1 Aug, 2024 | Systems & Technology
 The decline in news audiences reported here – 43%, or 11 million daily views – is shockingly high. This follows Canada’s ill-considered battle with Meta, which led to Meta pulling news from its platforms, including Facebook, in the Canadian market last year, rather than arrange content licensing agreements with news publishers.
The decline in news audiences reported here – 43%, or 11 million daily views – is shockingly high. This follows Canada’s ill-considered battle with Meta, which led to Meta pulling news from its platforms, including Facebook, in the Canadian market last year, rather than arrange content licensing agreements with news publishers.
This amply demonstrates the vast power these tech platforms have in society and over the media industry, and so justifies the Canadian government’s worries. But it also more than shows – once again – how utterly dependent the online content ecosystem is on these channels for distribution.
Meta/Facebook obviously isn’t a monopoly, but a 43% decline in news consumption thanks to the shutting down of one set of distribution channels? It’s a safe bet that much of the rest of the traffic will be from Google, so it’s more of a duopoly.
What impact is this level of reliance on a couple of gatekeeping tech platforms – who can change their policies on a whim at any time – going to have on public awareness of current events and society at large
Elsewhere in the article we have an answer: “just 22 per cent of Canadians are aware a ban is in place”.
Shut down access to news, little wonder that awareness of news stories stays low.
Both Canada (with Meta) and Australia (with Google and Meta) have tried forcing the tech giants into doing licensing deals for content that their platforms promote. In both cases, this has – predictably – backfired, and led to the opposite effect to that intended.
But what’s the solution?
This question is becoming more urgent now that GenAI is in the mix, and starting to provide summaries of stories rather than just provide a headline, image, and link.
Meta/Google were effectively acting like a newsstand – showing passing punters a range of headlines to attract their attention and pull in an audience.
GenAI’s summarisation approach, meanwhile, is much closer to what Meta and Google were being (unfairly) accused of doing by the Canadian and Australian governments: Taking traffic away from news sites by providing an overview of the story on their own platforms.
But the GenAI Pandora’s Box has already been opened. Publishers need to move away from wishful thinking – the main cause of the failed Australian/Canadian experiments – and back to harsh reality.
Unlike the Meta news withdrawal – which could be reversed – this new threat to content distribution models isn’t going away.
by JCM | 31 Jul, 2024 | Systems & Technology
 “If your website is referenced in a Perplexity search result where the company earns advertising revenue, you’ll be eligible for revenue share.”
“If your website is referenced in a Perplexity search result where the company earns advertising revenue, you’ll be eligible for revenue share.”
How many qualifiers can be fitted into one sentence, all while providing next to no information?
To be clear, I’ve loved WordPress ever since I migrated my old blog to it [checks archives] *18* years ago [damn…] I also fully get why they’re doing this – some money is better than none, it may work out, and it may actually lead to more traffic / engagement / visibility for WordPress sites.
But this all feels a little like promises of scraps falling from the table of people who are getting scraps falling from an even higher table.
Perplexity currently claims to be making US$20 million from paid subscriptions to its pro service – about the only source of income it currently seems to have, despite its $2.5-3 billion valuation. If they’re now giving away some of that limited income, I can’t see an obvious path to profitability, given the hefty running costs of GenAI.
This doesn’t just go for Perplexity, but for all these GenAI tools:
- What’s the path to a sustainable content publishing-based business model (and all these GenAI companies are content companies) when being able to produce infinite content on demand means the traditional route for making money for these kinds of companies – advertising inventory – is also infinite?
- Value comes from scarcity. Content / as inventory is no longer scarce. How do you make something that’s not scarce seem valuable enough to get people to pay for it?
- And when all GenAI models offer more or less the same output, and more or less the same level of reliability, and successful features and approaches can be replicated by the competition in next to no time, how do you stand out from the crowd?
Being a content/tech geek I’ve been thinking about this a lot over the last couple of years. Perplexity’s approach is one I like (I did history at university, so I love a good list of sources, even if they’ve mostly just been added to make your work look more credible and most of them are irrelevant, as is often the case with Perplexity) – but I’m far from convinced it has money-making potential. As Wired has put it, Perplexity is a bullshit machine. How valuable is bullshit?
Basically, we’re firmly in the destruction phase of creative destruction. The creative part is yet to come
But still – at least the providers of the raw material these LLMs are so reliant on are starting to get thrown a few bones. That’s a step in the right direction – because as that recent Nature study made clear, the proliferation of AI-generated content risks surprisingly rapid synthetic data-induced model collapse.
Human-created content may no longer be king, but it remains vitally important. Without it – and a hefty dose of critical thinking – the whole system comes tumbling down.
by JCM | 15 Sep, 2020 | Systems & Technology
This long piece neatly sums up the paradox of the age of algorithmic analytics:
“Algorithms that tell us which topics are trending don’t merely reflect trends; they can also help create them…
“The internet has shown us that the oddest of subcultures and smallest of niches can develop followings… I don’t think readers weren’t interested. It’s that they were told not to be interested. The algorithms had already decided my subjects were not breaking news. Those algorithms then ensured that they would never be.”
This approach of following your analytics is a *terrible* content strategy. By pursuing a mass audience and popularity above all, same as everyone else, you’re doomed to lose your distinctiveness – and relevance to your true target audiences. Even though the algorithms supposedly love relevance above all, they’re still (usually) not sophisticated enough to identify your priority audiences among all those visits.
This is why we’re seeing so many traditional publications fail, and ad revenues collapse: They’ve all become alike, because the algorithms have told them all the same things. That’s made them less valuable, in terms of both price and utility.
Don’t get me wrong: audience analytics are essential. But you need to know how to read them – and their limitations.
by JCM | 21 Aug, 2020 | Systems & Technology
Being a words person it’s unsurprising this piece spoke to me, as it advocates using words as an accessible tool – Google Docs – to improve creative collaboration.
Yes, at its heart, this place is basically saying that a collaborative design/multimedia/dev briefing doc is a good idea – and it’s hard to argue against that.
But it also speaks to a core challenge in the digital creative industries – especially now we’re all working from home and can no longer scribble on whiteboards and move post-it notes around on walls:
What’s the best way to collaborate when developing visual concepts? How can we lower barriers to entry for those with less confidence in their visual thinking skills? How can we encourage more diverse thinking, more originality, while still staying focused on the core objectives?
I’d be fascinated to hear your suggestions / recommendations.
by JCM | 12 Aug, 2020 | Systems & Technology
PDF: Still Unfit for Human Consumption, 20 Years Later
Punchy title and many good points made. But PDFs are an easy target.
It’s also ironic that in attacking PDFs as clunky, hard to read in a browser, and bad for mobile, the authors have created a 2,400-word monster without a single engaging image or design element to break up the wall of text. And they’re so keen to make their point as robustly as possible that a few too many arguments are piled on top of each other – some rather weaker than others.
The point they miss is format needs to be led by function – the medium isn’t the message, but it does shape it. For some functions, a PDF is a better option than HTML, for others a simple email may be best. Your format should depend on your objective, target audience, and what impression you want to leave them with.
Most importantly, *presentation* also needs to be shaped by format, audience, and objective. Sometimes, better a PDF where the design is fixed than responsive HTML that messes up your careful layout when your key client views it on their ancient IE6-running machine. (Bitter experience…)
If you want to persuade, your thinking and presentation always need to be good, no matter the format. Sloppy content structure, sloppy design and sloppy thinking will undermine your objectives far faster than a PDF ever will.
by JCM | 29 Jun, 2020 | Systems & Technology
The most surprising thing with this growing move away from social media advertising is that it has taken this long for brands to realise that they can’t control the context in which their adverts appear – and that context can change perception of their messaging.
The real lesson here is not that social media needs stricter controls (an ethical debate), it’s that in the classic Paid/Earned/Owned model, the *only* part brands can fully control is Owned. Many are only now beginning to wake up to the fact that their social accounts are not Owned platforms.
All this should have been obvious for years – every fresh story about an algorithm change destroying business models that were relying on social audiences has been an alarm bell. But perhaps now brands are finally realising that social isn’t as straightforward as they’ve long seemed to believe.
What does this mean for brands?
1) They need more robust, nuanced social strategies. Chucking money at paid posts and adverts doesn’t cut it. It never has.
2) The quality of their genuinely Owned platforms is becoming more important than ever. These are the only places they have complete control over the context and the message.
And it’s also notable that many brands joining the boycott have solid Owned strategies in place…
by JCM | 7 May, 2020 | Systems & Technology
“I haven’t witnessed an update as widespread as this one since 2003,” says the author of this piece. Some sites are reporting 90% traffic drops, with even the likes of Spotify and LinkedIn apparently impacted. This is big.
What exactly has changed is still unclear – a few days on results are still fluctuating too much for detailed analysis – but one thing does seem certain: “there are multiple reports of thin content losing positions”.
This has been the trend with Google for a while now, with the firm recommending “focusing on ensuring you’re offering the best content you can. That’s what our algorithms seek to reward.”
What *is* good content in this context? After all, “quality” is quite a subjective concept.
Well, algorithms aren’t people, but Google’s long been aiming to make their code more intelligent, and better able to understand context and likely relevance. Keyword stuffing has been penalised for years, as have dodgy link-building efforts. Instead, Google is aiming for near-human levels of appreciation of nuance.
Helpfully, though, Google has also put out a list of questions to help you understand if the content of your site is likely to be seen as quality in the eyes of the all-powerful algorithm:
- Does the content provide original information, reporting, research or analysis?
- Does the content provide a substantial, complete or comprehensive description of the topic?
- Does the content provide insightful analysis or interesting information that is beyond obvious?
- If the content draws on other sources, does it avoid simply copying or rewriting those sources and instead provide substantial additional value and originality?
- Does the headline and/or page title provide a descriptive, helpful summary of the content?
- Does the headline and/or page title avoid being exaggerating or shocking in nature?
All good questions, and all from Google’s own blog.
