Bad photo of a good slide on what makes content valuable in an AI era, from Kevin Anderson at the inaugural Source Code event last night.
A successor to the much missed Hack/Hackers series looking at how tech and journalism can come together to do great things, it was unsurprisingly dominated by conversations about AI.
The point about what is valuable about the content we produce was also core to my old colleague Steven Wilson-Beales‘ session on SEO / GEO / AEO / AIO / whatever you want to call it, and what a “zero click” web could look like in practice.
Key points:
– You need differentiation
– You need to add value
– You need to be accessible, relevant, and credible
It’s almost as if E-E-A-T is still a thing!
Also, the lesson we should all have taken from the last decade and a bit of chasing search and social algorithms is simple – diversify.
Don’t get over reliant on any one traffic source. Don’t chase the algorithm, because the algorithm is changing faster than ever – and with AI search, will increasingly adapt it’s findings to every individual.
And a top tip – given AI tools have been trained on existing content, you need to take a careful look at your archives. If they don’t answer the potential needs of an AI bot in query fan out mode, they may need an update.
—
But the absolute key point – and this speaks to a lot of the work I’ve been doing behind the scenes lately – It’s no longer enough to focus your SEO / GEO efforts on optimisation of individual pages.
You need to see your content as part of a broader system – because the bots are no longer looking for just one page to rank at the top of a list, they’re looking for the right information to answer the query. If they can’t get it from you, they’ll get it from someone else. (Or just make it up…)
This brought back fond memories of the Bullshit Bingo tracker we used to keep to try and steer clients (and ourselves) away from jargon when working on B2B projects back in my Group SJR days…
Simple, jargon-free language is almost always the best option if you want your message to be understood – but it can be hard to get it past approvers, because the more you simplify the language, the clearer the strategic recommendations become.
For some, this clarity feels like a risk – because the best strategies tend to be very simple, once you strip them of all the linguistic fluff. This is where and why business bullshit creeps in – to make the clear seem complicated, so the person presenting seems like they’re better value for money.
Of course, what this all misses is that devising the strategy *is* the easy bit (relatively). The hard part is getting others on board to start rolling it out, and to ensure the organisation as a whole doesn’t just adopt it as a mantra, but understands and acts on it.
This is why strategic development needs to take its time – the conversations and debates that inform a strategy are the first step towards helping the broader organisation accept it.
Put lots of jargon in your explanations, you’re creating barriers to understanding and adoption.
But equally. there’s always a risk that someone will call you on it – and reveal that underneath all the convoluted wording, you’re really not saying much of substance. That’s surely a far bigger reputational risk than showing you have the insight to cut through to the heart of the matter with a clear, simple strategic recommendation.
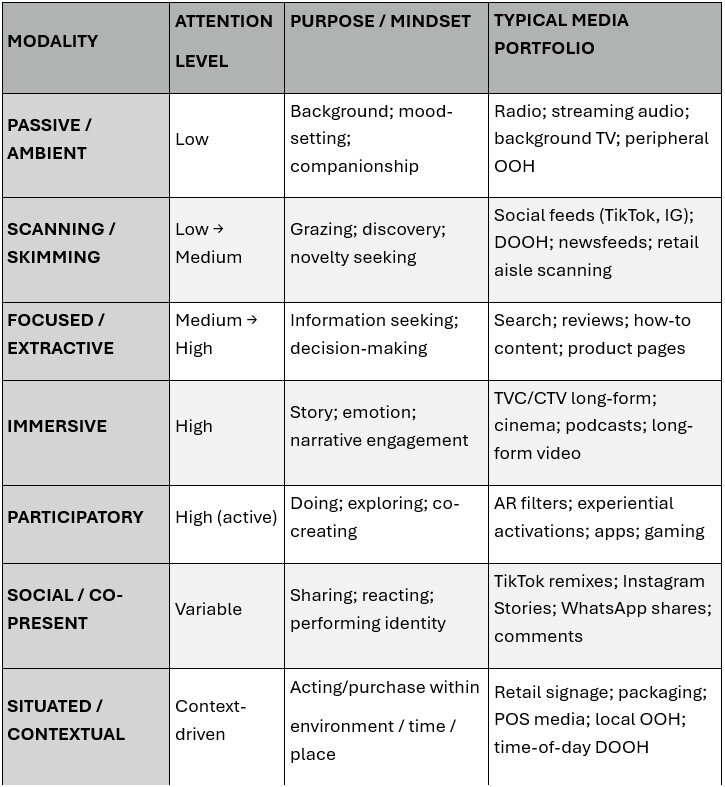
Thinking of media channels as cognitive environments – shaped by context, attention and mode of consumption – is a useful perspective shift, from this piece by Faris Yakob, via WARC.
I also like Yakob’s framing of modality (how something is experienced), momentum (how it builds), and moments (how it comes into focus). But beneath that, this still feels largely like optimisation thinking – just applied to modalities and moments rather than formats and placements.
The part that matters most for brand-building is momentum, and that’s the least clearly explained. How do ideas actually build over time across different environments, teams, markets and formats? What creates momentum deliberately and consistently – the long as well as the short of it – connecting one “moment” to the next, beyond loose consistency or a set of distinctive assets?
This need for sustained momentum becomes more obvious in B2B contexts, where “moments” are harder to engineer, cycles are longer, and distinctiveness can be difficult – even risky – to pursue.
In those environments, the question is whether the organisation can produce and sustain a coherent narrative across everything it does, over time.
That isn’t really a media or creative (or modality or moment) problem – it’s structural.
It comes down to how narratives are defined, how topics are prioritised, how content is developed and reused, and how different teams interpret and apply the same underlying ideas over time, not just over campaigns or activations.
In other words, it’s about the architecture of the system that generates the communication, not just the optimisation of what gets put into it.
Without that, modality and moments are useful lenses, but they don’t explain why some brands build momentum while others just generate activity.
I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
These systems don’t just read what you publish and serve up the most relevant parts – they synthesise it, blending multiple sources based on patterns they infer across a wider field of signals:
– everything you publish
– everything others publish about you
– everything they consider adjacent or comparable
They’re also not just looking at what’s being said now. They’re conflating and combining the accumulated traces of how your organisation expresses itself over time – across campaigns, content, product information and everything in between.
Repetition and consistency may help, but they won’t just pick up what you intend. They absorb whatever is most legible – including contradictions, gaps, and overlap with competitors.
If your positioning isn’t distinctive, you’ll get flattened into the category. If your communication isn’t coherent, the model will reconstruct a version of your brand from whatever patterns it can find. And when it comes to facts and details – where accuracy actually matters – these systems are still unreliable enough to pose a real risk.
This is where a focus on structured data starts to look like a promising way forward. That was my first assumption. But it’s becoming increasingly clear that this isn’t going to be enough.
—
The key is to remember that these systems don’t *understand* information. They generate outputs by following probabilistic sequences – patterns shaped by the data they’ve seen.
It’s a sophistiated form of word association. Structure helps, but only where it clarifies those patterns to nudge the model to follow the path you’d prefer.
Over time, what you’re really creating – deliberately or not – is a set of associations the LLM learns to treat as related. What we’d normally think of as a brand “narrative” sits inside that – not as something the model understands directly, but as a pattern of connections it learns to reproduce.
—
This means “AEO” should be considered less about optimising individual outputs, and more about the long-term shape of the signals you generate – across teams, markets and years.
I’ve been doing some work on this recently, trying to make that problem more tangible and diagnosable in practice. Still early, but the direction of travel feels clearer.
The brands that show up well won’t just be the ones optimising for visibility. They’ll be the ones whose overall pattern of behaviour is coherent enough that even a probabilistic system can’t easily misread what they are.
As this is a book of fairly straightforward, slightly gushing interviews with various people from the world of marketing, this would today have worked much better as a podcast. In this format it feels pretty repetitive as well as being dated (first published in 2011, with some of the focus on social media as if it’s new and Apple as if it’s a challenger brand feeling really rather quaint.
There probably were some actively thought-provoking points made somewhere in here, but everyone blurred into one in the end. so I have no idea who said what, and nothing really stood out – except the guy who was very vocal about his dislike of Daniel Kahneman and the idea of Behavioural Economics.
Of course, these “insights” may have seemed more radical 15 years ago. And for newcomers to marketing they still might.
But it’s notable how much of what’s said here sounds fine in theory but feels very hard to turn into tangible takeaways that people trying to build brands themselves could actually use. It mostly all ends up sounding like fluff and cod psychology. You can see how marketing and branding ended up getting a bit of a bad name if this is the best they had to offer.
Then again, maybe it’s because pretty much everyone featured here is American? As Mark Ritson – today’s leading marketing advocate – keeps saying, American marketing and advertising hasn’t been particularly sophisticated for decades.
In short, useful to read if in the profession, but there’s very little surprising, practical or inspiring here. It’s mostly pretty obvious platitudes.
Most of what the “GEO” crowd are peddling now *sounds* logical with all its talk of structured data and query fan outs, and is more or less exactly what I was arguing back in late 2023 / early 2024.
I was wrong then, and they’re still wrong now. As Orange Labs founder Britney Muller puts it:
During training, LLMs process text from across the web, but they don’t log URLs, store sources, or remember where anything came from. What’s left is a frozen statistical snapshot (Gao et al., 2023). Not an index. Not a database.
Search engines do the crawling, indexing, and retrieval. LLMs lean on them heavily to surface real-time info (because on their own, they can’t).
Stop optimizing for ‘AI.’ Optimize for search engines (so retrieval-based AI can cite you) + earn third-party coverage (so the model already knows you before the prompt is typed).
That’s not to say query fan out logic (and other “GEO” tactics) doesn’t have its place in content planning – it does. But all this *really* is is a fancy name for an FAQ page (with less emphasis on the “F”). That’s been a core idea in SEO for over two decades. And pretty much all the rest of the “GEO” advice is similarly reskinned old school SEO – from keyword stuffing to linkfarm spamdexing – that Google quietly filtered out years ago.
There’s an awful lot of snake oil being flogged out there at the moment. If some of it seems to work, it’s more by accident than design.
I initially loved this – effectively a popular historiography of the (Italian, mostly) Renaissance, exploring different perspectives and opinions and how these have evolved over time – while also providing overviews of some of the key events and personalities.
This is a wildly confusing period, so this approach actually works pretty well – highlighting who focused on what and offering multiple explanations as to why. Until about halfway through I loved it, and still remain convinced that looking at history by first looking at the lens of the historians and players who shaped that history is an approach more popular history books should take, rather than just run with a narrative.
But… “The Renaissance”, singular? This goes totally against the author’s core argument, which is all about how there are any number of ways of looking at this period (or even defining how long a period we’re talking about). Yet despite this we get surprisingly little about the Northern Renaissance, and almost every key figure called out was based in northern Italy – despite multiple references to Erasmus as a nexus of Renaissance correspondence, we get few investigations into how or whether what was happening in Italy was influenced by or influenced what was going on elsewhere (bar the frequent French invasions and other aspects of high politics).
Equally, about halfway through I started to find the whole thing a little overwhelming as we jump from overarching thesis (there’s no one right way of interpreting any of this) to detailed biography, so philosophical aside, to onrunning jokes. After a promising start, the structure starts to get lost, and it increasingly feels like a series of essays or blog posts loosely bound together.
The more this went on, the more I felt it could have been better if presented as essays rather than a whole – because after a while the running jokes (“Battle Pope”, “Abelarding”, references to Game of Thrones, etc etc) start to detract from rather than clarify the argument. This jokey style is one that’s been very popular the last decade or so, and can work – but in a book this long it can start to grate, even if you don’t object to it in principle, as some might.
Which is a shame, because there’s a lot of really good stuff in here. I learned a lot, and will want to go back and re-read various parts (as long as I can work out which with the jokey chapter titles) to refresh my memory – and eventually start to make a little more sense of a chaotic and challenging to understand period.
This, on the resurgence of the Rise of the Robots fears about the threat of widespread AI job losses, gets some of the way to articulating the niggling issues I have with this apocalyptic narrative:
Even if you do believe the technology has got or can get good enough to replace workers at scale, the economics simply don’t make sense.
Of course, we’ve spent the last two decades witnessing many, many things that made no economic sense yet that happened anyway thanks to a combination of complacency, willful ignorance, ideology, bloody-mindedness, and spite. Just because something makes no economic sense doesn’t mean it won’t happen.
But despite non-AI industry stocks having been hammered over the last couple of weeks, think what needs to happen to enable this AI revolution. Most developed nations had energy and clean water supply challenges even before factoring in a data centre building boom. We still have a deep reliance on rare earth metals for the hardware that the AI needs to function (the clue’s in the name).
What happens to prices when demand surges to unprecedented levels and supply struggles to keep up? And how does that change the balance sheet projections when deciding whether to replace human workers with a grandiose form of a new SaaS subscription, whose monthly costs and reliability could shift at any moment?
Remember the $7 *trillion* Sam Altman was asking for to invest in infrastructure? That’s likely to be a substantial under-estimate of the amounts needed given how much every industry upstream of the AI companies is already struggling to meet their projected needs.
History is all about perspective, and perspectives. This history of England’s most turbulent century – a period I studied to postgrad level – is a welcome attempt to offer alternative views of events via the eyes of non-English observers. As we’re somehow still referring to the central event as the English Civil War – ignoring Scotland, Ireland and Wales – this is very much needed.
The introduction promised a lot, and got me genuinely excited to see how much this focus on foreign perspectives – and foreign policy – would shift my own understanding. But while there were some new things for me here, at its heart this was all rather familiar.
Then again, I’m not really the target audience. As well as having studied the period, I also spent some time plotting out a potential novel that hinged in part on the foreign policy of James VI/I and the (limited) British involvement in the Thirty Years War.
For anyone relatively new to the period, or looking for a refresher overview, this would be really rather good. Standard accounts do tend to focus almost exclusively on England, where here Scotland and Ireland (not so much Wales) do get their due. But more importantly, most accounts tend to obsess about the religious angle, the disputes over tax and revenue, the disputes about the limits to the power of the monarchy, the attempts by parliament to assert itself.
All those are present here too – but so too are explorations of the European horror at the execution of Mary Queen of Scots; the Spanish side of the Spanish Armada and the Spanish Match, as well as worries about the subsequent French marriage; general concern as the civil wars broke out and further horror at England’s execution of a second monarch in sixty-odd years; the Dutch rivalry and wars and invasion.
All this is necessary to a solid understanding of the era – but all too often is skipped over or sidelined. Here, while it’s still not foregrounded as much as I’d hoped – or as much as is promised in the introduction – it’s hard to avoid the fuller understand appreciation that England was not operating in isolation. That other countries existed even then, and that even the foreign relations were far more than just theoretical, largely religious concerns.
All that said, cutting this off with the Glorious Revolution (another bad name that’s stuck) makes zero sense from a non-English perspective (even if the epilogue continues the story through to George I). Logically, the cut off should be more like 1745 (that final Jacobite rising, in the midst of British involvement in the War of Austrian Succession) and the solidification of the Hanoverian dynasty, or even a century later with the death of the Young Pretender / Bonnie Prince Charlie. But I guess by that point Britain was so firmly involved in European and global affairs that the emphasis on non-English opinions about the English would hardly be surprising.
So, a good overview – even if sadly not as radical and overhaul of the period’s traditional narratives as I was hoping.
Back when ChatGPT 3.5 came out, I was telling anyone who’d listen that it was going to disrupt search and publishing.
In early 2024, while at PwC, I started pitching new content formats to address this – intended to help capture whatever the GenAI equivalent of search ranking was going to be. “GEO” before this label stuck (I was calling it AIO at the time).
My thinking then was based on what seemed to be a logical, structured approach – similar to the “query fan out” advocates you’ll see in the “GEO” space today. (Basically label the hell out of your content, anticipate and answer the questions your target audience is likely to ask, as that structure should help the AI understand the context more easily, and so encourage it to pull from your page rather than someone else’s. Effectively a slightly deeper version of an old school Q&A or FAQ piece…)
But as I dug deeper it soon became clear that the challenge with LLM-based GenAI (from a model visibility perspective) wasn’t to do with clarifying the intended meaning of the information you want the model to ingest and regurgitate, as I first thought. (“These things can process unstructured data, but they’ll process *structured* data easier – so let’s structure it for them.”)
Instead it’s that these systems – despite being called Large *Language* Models – don’t actually understand language, or context. “Logic” to them is a meaningless concept; not only that, they have no concept of what a concept even is.
—
Tokens aren’t words, and don’t have meaning independently – they only appear to have meaning when combined into words.
Tokens create the illusion of being words (and having meaning) because of the probabilistic nature of these tools, when working with them using language as the system interface. This creates an environment in which they’re working within the rules of language, so can produce output that makes sense – even if they don’t “understand” what they’re saying.
But URLs aren’t language, and don’t have linguistic rules or any consistency from site to site in terms of information architecture. Every site’s URL structure is similar, but different.
And as LLMs don’t really understand structure (except as recognisable, predictable patterns), this makes accurately relating URLs a significant challenge for current LLM-based GenAI tools.
—
This is a structural challenge, baked into the very nature of these models. Despite what many GEO “experts” are now claiming, if your goal is to generate links and traffic from GenAI results, it’s not going to be an easy one to engineer if you’re working from outside that system.
It may be possible to tweak model outputs to improve this and increase URL attribution accuracy, but a) it won’t remove the underlying structural constraints, and b) what would be the incentive for the GenAI companies to do this?
To help shape my thinking, I write essays and shorter notes examining the ideas and narratives that shape media, marketing, technology and culture.
A core focus: The way context and assumptions can radically change how ideas are interpreted. Much of modern business, marketing, and media thinking is built on other people's frameworks, models, theories, and received wisdom. This can help clarify complex problems – but as ideas travel between disciplines and organisations they are often simplified, misapplied or treated as universal truths. I'm digging into these, across the following categories - the first being a catch-all for shorter thoughts:


 I also like Yakob’s framing of modality (how something is experienced), momentum (how it builds), and moments (how it comes into focus). But beneath that, this still feels largely like optimisation thinking – just applied to modalities and moments rather than formats and placements.
I also like Yakob’s framing of modality (how something is experienced), momentum (how it builds), and moments (how it comes into focus). But beneath that, this still feels largely like optimisation thinking – just applied to modalities and moments rather than formats and placements. I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?
I’m seeing more and more people realise that “AEO” (Answer Engine Optimisation”) is just SEO in new clothes. But are GenAI outputs even something you can optimise for?

